


 Steve Neemeh
Steve Neemeh
Why ISO 26262 Part 2 is the most critical for your company
Part 2 of ISO 26262, Management of Functional Safety, is the critical one for your company to initially embrace, even though 12 parts exist within ...

Functional safety consists of automatic protection systems that are part of the overarching safety of a system or a piece of equipment. Despite the scope of the standard implying a deference towards electrical engineering, mechanical engineers have a critical role to play. To be most effective, there are key principles that mechanical engineers must understand.
This is the first article in a 2-part series focused on the role that mechanical engineers play in quantifying and achieving functional safety:

Automotive technology has undergone a sweeping evolution since the mid-20th century, at a pace that continues to increase. For some time, vehicles have been electromechanical, combining both electrical and mechanical systems. However, today’s modern vehicle has evolved into a mechatronic system that marries electronics, mechanics, and computing, to provide a vehicle that is smarter, more economical, and more reliable.
ISO 26262 specifically states that the standard is only applied to electrical and/or electronic (E/E) systems that are installed in series-production passenger vehicles. “Electrical and/or electronic systems…” that is the scope of the standard, seeming to indicate that it is not for mechanical engineers. And this is reinforced throughout the standard, as every separate section within always starts with this scope. Yet sometimes, having awareness of what is not in our role, is as informative and impactful as what is explicitly defined as being within it, especially at the borders where the scope of one role interfaces with another. This additional perspective provides useful context as we strive to identify and achieve what we are supposed to do, and the most effective way to do it.
The confusion is understandable. After all, ISO 26262 goes so far as to detail some of these exclusions, and then reinforces them at the beginning of every section. For example, it doesn't apply to electric shock, fire, smoke, heat radiation, toxicity, flammability, reactivity, corrosion, release of energy and similar hazards. But then it says, “… unless directly caused by malfunctioning behavior of E/E safety-related systems.” Honestly, I don't know how a failure doesn't relate to software and electronics, because no matter what system you have, there's a driver there, and there's a detection mechanism present that is coming from some sort of controller. So, it's going to be very hard to separate these. But it does say all of that in the specification, so if you're a mechanical engineer, you might be tempted to think that you are off the hook. Not quite. Let's go back and revisit some of the specific parts of this standard that tie back to mechanical engineering.
To determine the probability of a fault causing a safety critical issue, ISO 26262 requires that all faults be analyzed and classified as one of six different types: “safe,” “single-point,” “residual,” “detected multi-point,” “perceived multi-point,” and “latent multi-point.” The terms used for describing the various faults can be confusing, so it is important to understand the differences. It is also important to note that the type of fault is relative within the context of a particular safety goal. A given fault may not be able to be categorized as being only one type that applies in all situations, as the same failure mode of the same hardware part could be a safe fault to one safety goal, but a single-point fault or latent fault to another safety goal.
A safe fault is a fault, by itself or combined with another independent fault, that with the absence of a safety mechanism, will not violate a safety goal. A safe fault is not necessarily a detectable fault, it could also be a non-detectable fault. The key is that a safe fault does not violate a safety goal. It does not have the potential to put the safety system in a dangerous or fail-to-function state, nor can it create a situation where it calls for the safety system to be shut down or a safety function to activate when there is no actual hazard present. Safe faults cannot impact safety critical functions either because they do not have a physical connection to a safety critical function, or they are masked along the way.
Single-point faults are at the heart of designing safety systems. A single-point fault creates a safety risk at a single point in the hardware architecture. In addition, detection plays a role. If there is a failure at that one point and there is no safety mechanism to detect it, will it cause a safety goal violation? If the answer is ‘yes,’ it is a single-point fault, and it must be accounted for in the design.
Safety mechanisms can detect a fault to prevent it becoming a single-point fault. However, if the diagnostic coverage of the safety mechanism is not 100%, it will not detect all portions of the fault. For the portion of the fault that is not covered by the effectiveness of the safety mechanism, that becomes a residual fault.
The standard defines how much work you have got to do and how robust the system must be. When designing electronics, it is important to remember that, of Automotive Safety Integrity Levels (ASIL) A, B, C and D, ASIL D is the most safety critical. The single-point fault metric measures the robustness of the design to both single-point and residual faults; in this metric, a higher number is better.
ISO 26262-5:2011(E); derived from Table 4, details the requirements as follows:
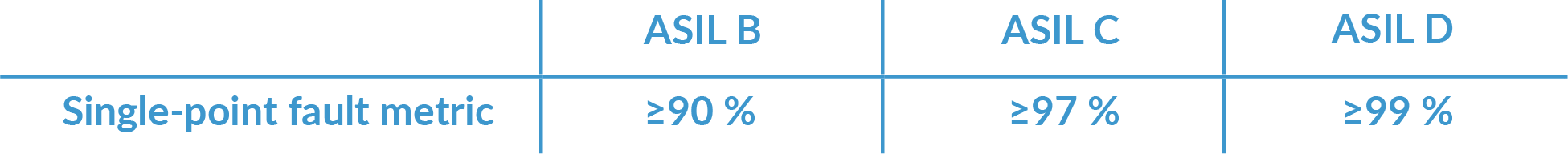
The purpose of these metrics is to evaluate the effectiveness of the system to prevent a safety goal violation. In this case, the purpose of the single-point fault metric is to control the total failure rate of the single-point fault and residual fault within an acceptable level. According to the mathematical formula for the single-point fault metric, it represents the percentage of the total failure rate of the multi-point faults and safe faults, in respect to the total failure rate of all safety-related faults. In the case that ASIL D has a target value of 99% for the single-point fault metric, that means that out of the total failure rate for all safety-related faults, the total single-point fault and residual fault failure rate shall be less than 1%.
The single-point fault metric is key for all safety-critical systems. They must be designed so that if one thing fails, there's a backup of some kind. There must be a way for you to save the person from harm in some way. That's the safety mechanism.
Multi-point faults include the fault itself combined with another independent fault that, when combined, can violate safety goals. The other independent fault can be but is not limited to, the fault in the safety mechanism.
There are three types of multi-point faults:
Detected multi-point faults are multi-point faults that are detected and corrected by the safety mechanism.
A latent multi-point fault is defined as a multi-point fault that cannot be detected by the system, nor perceived by the driver, and can violate a safety goal. Technologically, logistically, and schedule- and budget-wise, it is not feasible to eliminate all single-point faults and latent faults. The standard allows certain risk to meet the target value per ASIL rating for the safety goal, so long as the risk is controlled to an acceptable level.
ISO 26262-5:2011(E); derived from Table 5, details the requirements as follows:
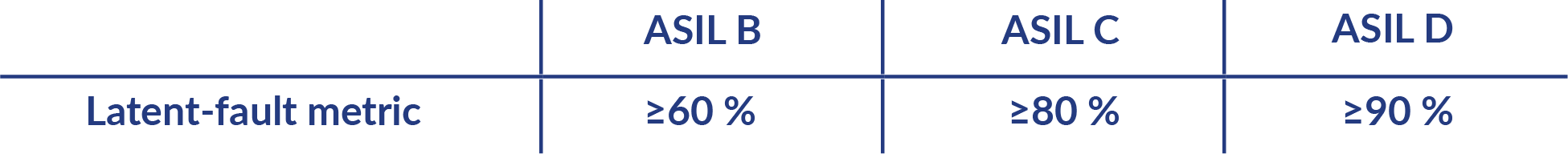
Perceived multi-point faults are multi-point faults that are not detected but have some noticeable impact on the driving experience.

How do you determine the probability of a given fault? How do you account for faults that you cannot detect? You calculate random hardware failures, a statistical computation of how many parts you have compared to the likelihood of them failing, and, the likelihood of the failure of those parts causing a safety issue.
The standard refers to this as the “Probabilistic Metric for random Hardware Failures (PMHF).” The standard tells you the percentages that must be maintained for different ASIL levels. The higher the ASIL level, the more stringent the requirement for the random hardware failure target value.
The way that the electronics engineers do this is by taking all the parts on the board and calculating the failure rate for each hardware part based on their characteristics and how each of them is being used in the circuit, combined with the mission profile of the vehicle. Then they perform combination calculations to figure out which one of these will ultimately lead to the violation of a safety goal. And, at what level. It's more of a statistical analysis than anything else, calculating the probability of one failure, then downstream, another failure. The incidents are then multiplied using methodical statistical calculation.
In Part 1 of this series, we have examined the evolution of the industry from electromechanical to mechatronic vehicles, the various types of faults, and random hardware failures. In Part 2 of this series, we will build upon this foundation and see how mechanical engineering ties into all of these considerations, and also review some specific and valuable lessons that have been learned.


Part 2 of ISO 26262, Management of Functional Safety, is the critical one for your company to initially embrace, even though 12 parts exist within ...

What are the key considerations for putting technical safety requirements to work

Part 2: Why Are Mechanical Engineers Important in Achieving Functional Safety? Introduction Functional safety consists of automatic protection...

How to Write Requirements for Functional Safety? What are the scope and purpose of safety requirements? The role of writing functional safety...

Electric Vehicle Considerations for Functional Safety Verification and Validation Testing The functional safety standard for the automotive industry,...
