


 Steve Neemeh
Steve Neemeh
Why is Safety at the Core of Software-Defined Vehicles?
Why is Safety at the Core of Software-Defined Vehicles? Creating technology can be a complicated and time-consuming process. At LHP Engineering...

Functional safety consists of automatic protection systems that are part of the overarching safety of a system or a piece of equipment. Despite the scope of the standard implying a deference towards electrical engineering, mechanical engineers have a critical role to play. To be most effective, there are key principles that mechanical engineers must understand.
This is the second article in a 2-part series focused on the role that mechanical engineers play in quantifying and achieving functional safety:

In Part 1 of this series, we reviewed the evolution of the industry from electromechanical vehicles to mechatronic vehicles, and some of the complexity brought about by this new technology. Yet as we read ISO 26262, the standard carries a recurring message that defines its scope as being focused on electrical and/or electronic (E/E) systems that are installed in series production passenger vehicles. The recurring use of the words “electrical” and “electronic” could be problematic, if one were to assume that these words alone defined the scope of the standard. At this point, mechanical engineers might be tempted to think they are off the hook. But that temptation must be resisted. Context plays a major role and once it is taken into consideration, the mechanical correlations become evident.
Electronic components are still physical devices, regardless of their electronic function. All these electronic parts… capacitors, resistors, processors, FPGAs… they're all physically mounted somewhere, and they are impacted by temperature and vibration. The failure rate of each hardware part depends on the physics of the part itself, rated parameters, design-oriented parameters, derated parameters, and the vehicle mission profile.
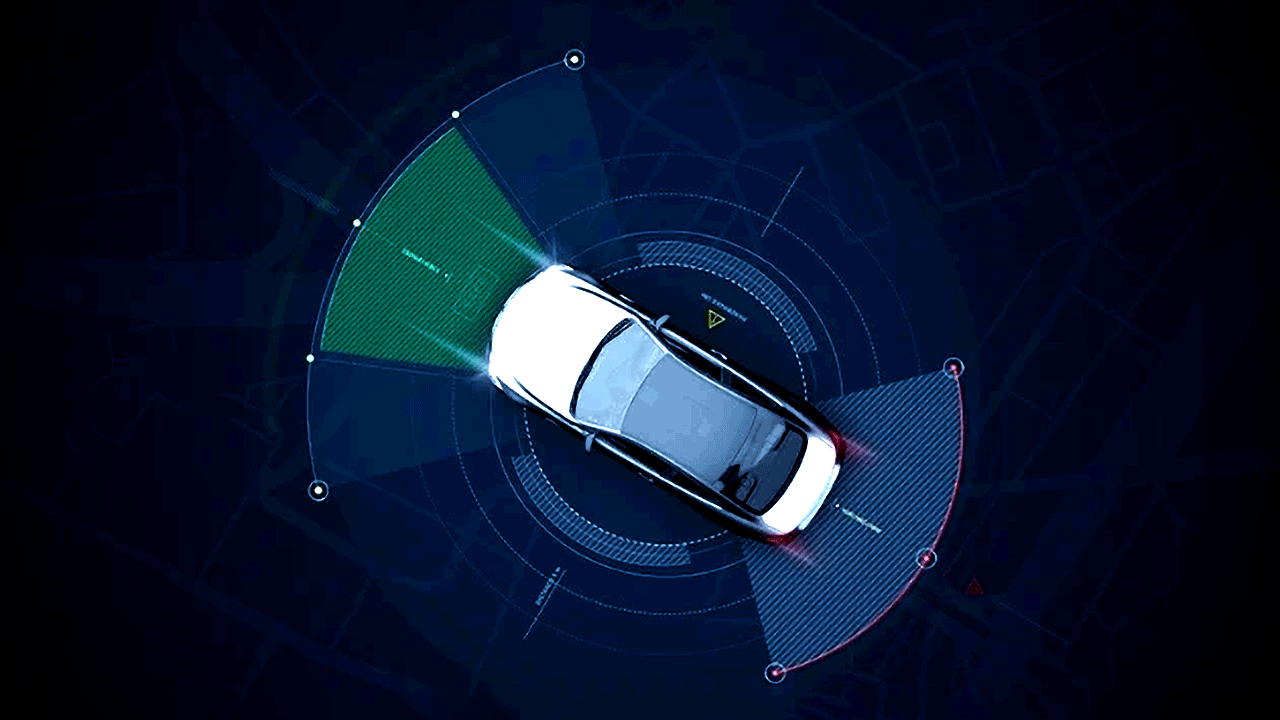
If you are building these electronics, and they are being placed in a harsh environment that includes high temperature stresses and frequent exposure to vibration, their probability of individual failure goes up and the reliability of each part and system goes down. As a system, the probability increases that the whole system may fail. So, where you mount your cameras, your light detection and ranging (LiDAR), and your other sensors, is a key consideration. The selection of mounting locations not only needs to consider how to protect the electronics from the environment, but they must also consider the mounting itself, the material selection of the enclosure, and the mounting location, in order to minimize interference among sensors and maximize sensor effective range and detection capability to improve safety.
As the engineer, I am seeking temperature profiles and vibration profiles, so I can estimate the Failure In Time (FIT) rate. There's a table that tells you the calculations for determining the failure rates for individual parts; see Table F.1 – “Possible combinations of sources of target values and failure rates to produce consistent failure rates for use in calculations” in ISO 26262.
In addition to providing the mathematical formulas for the calculations that need to be performed, this table also identifies the accepted data sources for the failure rates of hardware parts. You can choose from a standard database, military handbooks, statistics, and expert judgement… yes, they devised a mathematical formula for human judgment!
What about field data? Field data collection will require a good service tracking system that tracks the number of field returns and enables engineers to conduct root cause analysis. With an entire circuit board being a replaceable item rather than a particular part on a circuit board, it’s hard to collect field data for failure rates at the hardware part level, nor are the resources typically available to do so economically.
Let’s examine a typical piece of electronics… the radar in an advanced driver-assistance system (ADAS). It has a card in it. There are two primary considerations for that card: temperature, and vibration. What range of temperatures is a given electronic component on that card going to be exposed to while on that vehicle over time? And how much vibration (both frequency and amplitude) must it tolerate to keep functioning properly?
It depends on the use case. For example, during the COVID year, my car has spent most of the time parked in my garage. This is a temperate space that consistently experiences moderate temperatures and humidity, and the vehicle itself has seen little operation over the pandemic year. In comparison, a commercial vehicle is going to be driven across the country under challenging conditions on an almost continuous use basis, with little to no respite. Even if both vehicles are equipped with the same radar system, these are two very different use cases for the same component. The usage of the vehicle must be defined, and the packaging must be designed around the use case.
Generally, when electronics are operated in hotter environments, they tend to last for shorter periods of time. With any electronics, you want them to operate at reasonably cool temperatures. In some past instances, this analysis has led to installing additional fans to aid cooling. If electronic components are kept cool, they tend to keep running for extremely long periods of time before they fail. So, someone must apply expert judgement and analyze whether additional cooling is needed.
Vibration is the other primary concern. Vibration can cause stresses that result in cracked or broken connections and components. You can put these electronics in a box, you can mount them on shock absorbers, or you can mount them straight to the engine. Regardless of where you consider mounting them, you must take into consideration the big picture. That component might fit in a given spot, but how much vibration is it going to experience there? What is going to happen to the internal element of the parts, the soldered connections, the joints, and all the manufacturing processes? What is going to happen when you shake and bake that system over time?

Something we haven't seen at all yet in autonomous driving, and maybe in a lot of cases for ADAS, is the failures over time. We haven't examined an ADAS system over 10 years’ worth of continuous use. Once that milestone is reached, we might see that the blind spot detector or the adaptive cruise control slowly stopped working at some point. We just don't have enough data yet. And there are other mechanical considerations too, such as exposure to rain or salt environments.
The mechanical engineering analysis, the finite element analysis, the thermal analysis, the vibration analysis… The accuracy of these analyses will form a more realistic mission profile and stress level that more accurately reflects what each hardware parts experiences in the design. Thich will help to calculate a failure rate that is closer to reality. In turn, this will ultimately lead to the three metrics that we talked about that are required for Functional Safety ASIL A, B, C, or D.
Three metrics calculations must be performed and they all require FIT rates. Even though failure rates can be obtained from different sources, the ones that are closer to reality have to be calculated by combining the industry-recognized ISO 26262 recommended failure rate model, with close-to-reality mission profiles, and design-dependent stress levels.
And so, the mechanical engineers have a real job to do here. Their job is to provide that protection by determining the proper profile, which then leads to the analysis, which then leads to three different metrics: single-point fault metric, latent-point fault metric, and the Probabilistic Metric for random Hardware Failures (PMHF).
There are several lessons that have been learned, and missteps that should be avoided:

Mechanical engineering practices, properly applied, would have prevented these incidents. A temperature analysis and vibration analysis tied into a proper safety analysis, as well as the involvement of human factor engineering in conjunction with the cooperation between electronics and mechanical design engineers, would have avoided these recalls and incidents, and many others that have recently been in the news. These examples illustrate the important role that mechanical engineers play.
When using standards to perform useful work, one must resist the temptation to focus on individual specialties alone, and instead, also digest the scope and intent of the entire standard, cover-to-cover. Engineering is a team profession. Only by reading beyond the scope alone and comprehending the overarching context, will the individual fully understand their role on the greater team. This knowledge is powerful. The strengths and ingenuity of the total engineering team must be leveraged to maximum effectiveness in order to advance and achieve true functional safety.


Why is Safety at the Core of Software-Defined Vehicles? Creating technology can be a complicated and time-consuming process. At LHP Engineering...

What is Competence Management? The term Competence Management is derived from the broader world of business at large. In the realm of automotive...

Intro

What is Tailoring in Functional Safety? The international standard that governs functional safety is ISO 26262-2:2018, “Road vehicles — Functional...
ADAS Verification and Validation
